
Artificial Intelligence
•
10 min read
Building Reliable AI Systems for Security and Privacy Reviews
AI is transforming security reviews. Learn how to structure prompts, enforce output normalization, and build guardrails that scale security and work in production without compromising trust.

Emily Choi-Greene

Half of all new code is now AI-generated. But security teams haven’t scaled to match.
As an industry, we ship more software, face greater compliance requirements, and integrate with more third-party vendors than ever before. Security teams, doing critical work, can no longer scale with manual reviews alone.
The obvious answer is to use AI tools to accelerate security reviewers. But there is a massive gap between throwing ChatGPT at the problem and building reliable AI systems. Hallucinations, untraceable reasoning, and non-deterministic outputs can turn a security tool into a liability.
Here’s how we’re solving this at Clearly AI.
Why security reviews don't scale anymore
Security teams were already stretched thin before AI. Now, with tools like Cursor and Claude Code, the scale is staggering. Cursor is now used by 53% of Fortune 1000 companies and generates over 100M lines of enterprise code daily. GitHub Copilot reports that half of all new code is AI-generated. That’s a win for innovation, but it also means a growing volume of code entering production without security review.
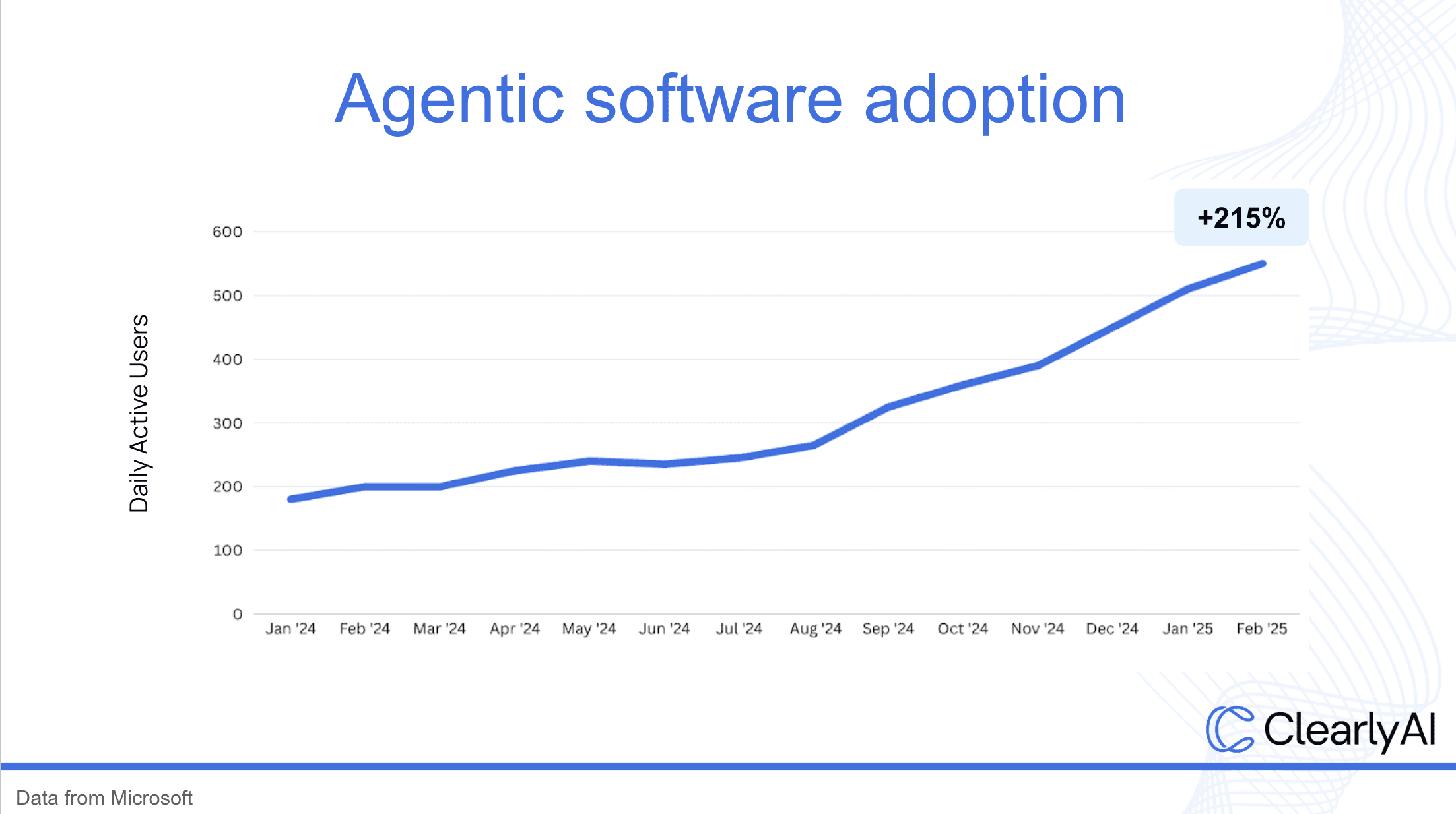
Data from Microsoft indicates a massive increase in agentic software adoption.
Manual security reviews worked when we planned features in quarters and launches in sprints. But when developers can turn ideas into entire microservices in minutes, security teams risk becoming a bottleneck or missing critical vulnerabilities that ship to production.
To match this new velocity, security teams need tools that can evaluate code, specs, and even ideas at scale.
Pick the right tool for the job
Building AI tools for security is like building AI tools for any other complex domain. It requires knowing when to actually use AI, when to use code, and when to call upon human judgment.
Where AI works best
Many security and privacy tasks have characteristics that align well with AI strengths. Privacy impact assessments, for example, require understanding diverse context types like codebases, documents, and diagrams. LLMs can ingest diverse formats and produce a normalized output that’s ready for review in seconds.
Well-defined, consistent workflows and frameworks like STRIDE represent a perfect use case for AI automation. LLMs can handle repetition at scale with infinite patience. They can process in parallel, in response, and on schedule.
Use AI to:
Convert unstructured data into structured data
Process large and vast amounts of diverse context
Handle unexpected situations at scale
Find patterns in messy data
Follow well-defined, structured processes, ad nauseam
Where AI struggles
Today, LLMs do not deal well with logic gaps and sparse context. Their output quality depends on the quality of their input. If available documentation is incomplete, noisy, or otherwise requires unwritten context or judgment, the task should escalate to a human expert.
While AI offers great scalability, it cannot yet match humans when it comes to judgment. Taste, values alignment, intuition, and social, organizational, and historical context are critical pieces of problem-solving, and humans do that best. They can better disambiguate and balance customer, business, and compliance priorities. When making risk tradeoffs, defining policies and specifications, or disambiguating, call on a human.
Call on a human for:
Critical judgment calls requiring values alignment, intuition, taste
Understanding social/organizational/historical context
Making risk tradeoffs and defining policies
Disambiguation where context matters
Tasks with unclear process or missing key information
Tasks with significant tradeoffs, with no clear “right” answer
What about code?
AI handles unstructured inputs and adapts to novel situations better than code. But it also introduces non-determinism, which adds engineering work. Production AI systems need evaluation, iterative tuning, and, for now, human monitoring to ensure reliability, completeness, and accuracy.
If code can handle the use case, it should. Code remains consistent, effective, and cheap. Code is becoming even cheaper with AI that can write the code for you. Whether handwritten or generated, code can be tested and even proven correct. Code behavior gets defined once, and then deployed. Code does not suddenly change unpredictably.
When you need a fixed deterministic output, traditional code can be a better choice than AI. These methods provide consistent, testable results and are easy to validate. At Clearly AI, we rely on deterministic logic to detect secrets in code or classify structured data fields, where precision and repeatability are non-negotiable.
Use code for:
Workflows that benefit from automation but don’t require interpretation
Functions that must behave the same way every time, regardless of input nuance
Tasks where probabilistic outcomes are not tolerated (100% not 99.95%)
Engineering reliability with LLMs
Determining which tasks AI can do well is the first step, but getting consistent, secure outcomes requires strong prompts and built-in guardrails. LLMs are prone to hallucination when left unchecked, so it's critical to structure their reasoning and validate their outputs.
Here are some of the techniques we use at Clearly AI:
Improve RAG outputs with tool use (function calling). Traditional RAG systems rely on semantic search to retrieve relevant documents, but embedding models aren’t great at fine-grained distinctions. When many retrieved documents are conceptually similar (e.g., several IAM policies or compliance checklists), the model may get overloaded with near-duplicates. Without task-specific retrieval or stronger filtering, even a well-prompted model is likely to misapply context or blend documents that should stay separate. At Clearly AI, we go beyond basic RAG. We use LLMs to orchestrate tool calls, request more targeted inputs, and validate retrieved context. This helps build context beyond the code to include what’s going on around it, who’s supposed to be accessing it, and more.
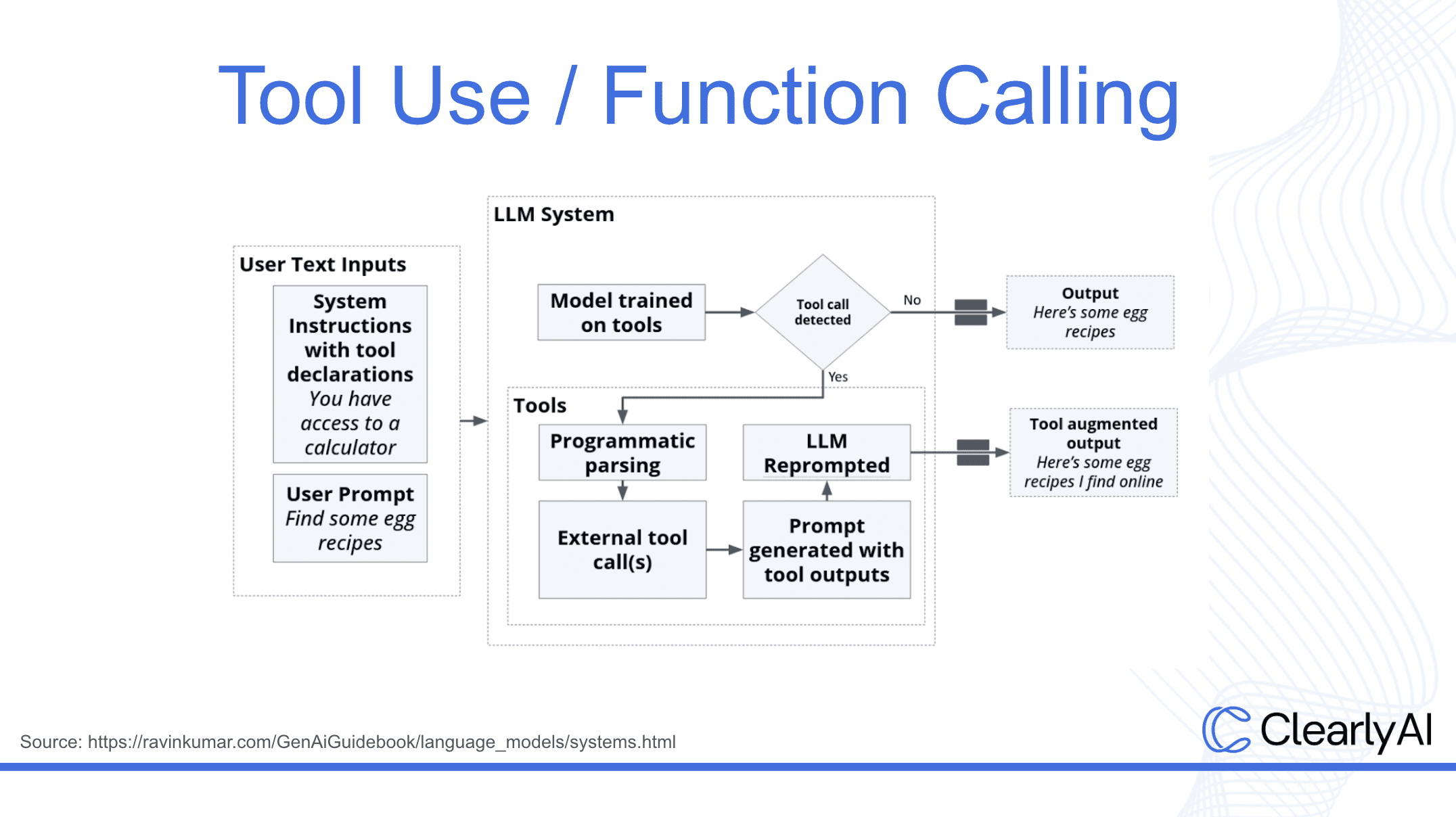
Chain-of-thought (CoT) prompting. Like asking a math student to “show your work,” CoT encourages the model to reason through a problem step-by-step, forcing the model to expand the problem space before generating a final output. Every time an LLM outputs a token, it's taking what's been said so far and guessing at the next statement. So once it gets off track, it's much harder for it to self-correct than to continue with the wrong answer. CoT reduces the likelihood of this happening by encouraging the LLM to "meander" or think out loud and consider a few directions before it commits. This reduces the chance of unsupported answers and makes the model’s logic easier to inspect and debug.
Explicitly design prompts to accept uncertainty. LLMs will hazard a guess if they are forced to answer. So it's best to give them an escape hatch, allowing them to admit when they don’t know. Prompt engineering must normalize behaviors like requesting more context, flagging incomplete information, or declining to answer definitively when appropriate. At Clearly AI, we also calibrate prompts to allow for varying levels of uncertainty, since a “pretty certain” can be more helpful to a human reviewer than a flat “unsure.”
LLM as Self Verification. Use a separate LLM call to check the first model’s output against source material to validate accuracy. It acts as a second set of eyes, catching hallucinations or inconsistencies before results reach a human reviewer. These layers help ensure that AI actually reduces risk, instead of introducing new uncertainty.
Getting consistent, actionable, grounded output.
To make LLM outputs useful for security reviews, structured output is essential. At Clearly AI, we treat output structure as a first-class concern. We use tools like BAML, an open-source framework for prompt-based systems, to enforce consistency across outputs and build normalization directly into our workflows.
Here’s how we structure the process:
1. Architectural Context
Ensure the model understands the system it’s reviewing:
Break down infrastructure types
Require file paths and line numbers for cited code
Extract relevant dependencies and tags for traceability
2. Vulnerability Categories
Tailor prompts to the specific risk areas being reviewed:
Excessive IAM permissions
Open ports or misconfigured firewalls
Overly broad IP allowlists or CIDR blocks
3. Normalize Output Format
Structure the findings so they’re immediately usable:
Match output fields to an existing database schema
Enforce consistent formatting for severity, location, and recommendations
Enable easy cross-querying and filtering downstream
4. Automate the Final Report (optional)
Have the LLM generate structured reporting directly:
Output reports tailored for reviewers, auditors, or compliance teams
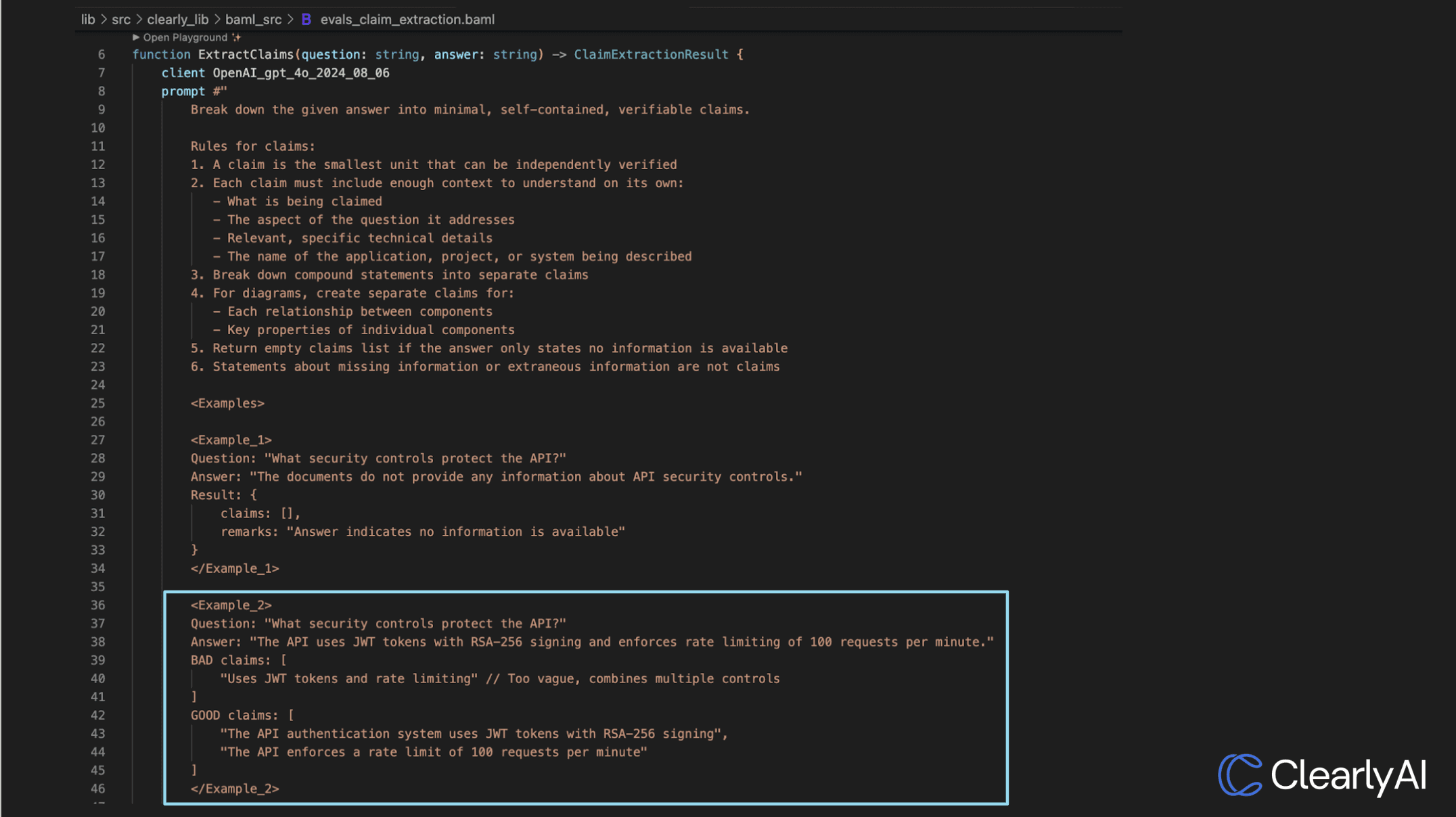
This layered approach keeps LLMs aligned with engineering expectations, protects against some forms of prompt injection, and prevents answers that break downstream systems.
For more tool recommendations, check out our AI Engineer Cheat Sheet.
Scaling security without compromising trust
AI can speed up workflows without reducing quality. But it requires disciplined implementation and ongoing scrutiny of its risks. Context engineering remains critical: if the input is incomplete, the output will be too. And there are familiar risks that take a new form with AI, like context poisoning. Applying AI responsibly means knowing where it adds value and reinforcing those areas with the right engineering controls.
AI is already reshaping security reviews, making the process faster, more secure, and more scalable. If you're ready to see how Clearly AI applies these principles in practice, contact us at support@clearly-ai.com for a demo.
To learn more, check out my talk on this topic at fwd:cloudsec this summer:
Related posts


Get the latest insights on security automation, AI-powered reviews, and
evolving regulations straight from the Clearly AI team.
